
Predicting Housing Prices 012 Data Prep Imputing Nans
import numpy as np
import pandas as pd
import warnings; warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import pickle
import lib.clean_helper as cl
import lib.viz_helper as vz
train = pd.read_pickle('../data/to_clean_2_train.p')
Imputing Nans
Dealing with nans that imply that we do not know a value.
is_there_nan = train.isnull().sum() != 0
train.isnull().sum()[is_there_nan]
LotFrontage 259
MasVnrType 8
MasVnrArea 8
BsmtExposure 1
BsmtFinType2 1
Electrical 1
dtype: int64
Few Nans in Electrical, BsmtExposure, and BsmtFinType2 Columns
There is only one nan each in Electrical, BsmtExposure, and BsmtFinType2 . This is an anomoly. We will just drop those observations. The dataset contains 1460 observations, so dropping at most three is trivial.
Electrical (Ordinal): Electrical system
SBrkr Standard Circuit Breakers & Romex
FuseA Fuse Box over 60 AMP and all Romex wiring (Average)
FuseF 60 AMP Fuse Box and mostly Romex wiring (Fair)
FuseP 60 AMP Fuse Box and mostly knob & tube wiring (poor)
Mix Mixed
is_straggler_nan = train[['Electrical', 'BsmtExposure', 'BsmtFinType2']].isnull()
to_keep = is_straggler_nan.sum(axis = 1) == 0
train = train[to_keep]
Nans in LotFrontage
From data description:
Lot Frontage (Continuous): Linear feet of street connected to property
In real estate, frontage is the width of a lot, measured at the front part of the lot. Every house has lot frontage. That means nans in that column means missing data.
Dealing with Missing Data
At first glance, you would think you can just ignore the missing data and do your normal calculations. We have lot frontage for 1200 of the 1460 observations in the dataset. We can just make do with the average of the 1200 values that we do know. However, just acting as if those unknown values do not exist actually affect our calculations more than not.
There is no one best way to handle missing data that works in all cases. Generally, one of our goals is to make our missing data be as innocuous as possible. Let’s act as if those nan values equal the mean of the known data.
train.LotFrontage.count()
1196
def hist_before_nan_to_mean(feature):
fig = plt.figure(); fig.add_subplot(1,2,1)
vz.hist_feat(feature)
dummy = feature.copy()
mask = dummy.isnull()
meann = dummy.dropna().mean()
dummy[mask] = meann
fig.add_subplot(1,2,2)
vz.hist_feat(dummy)
hist_before_nan_to_mean(train.LotFrontage)
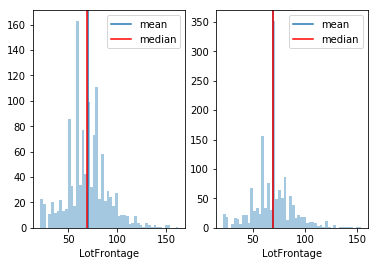
meann = train.LotFrontage.mean()
train.LotFrontage = train.LotFrontage.fillna(meann)
MasVnrType and MasVnrArea
MasVnrType: Masonry veneer type
BrkCmn Brick Common BrkFace Brick Face CBlock Cinder Block None None Stone StoneMasVnrArea: Masonry veneer area in square feet
There are two houses described as having some type of masonry veneer and masonry veneer areas of zero. That seems to be an error. Because there are only two observations with that error, we will just drop those two rows.
def check_nans(name_of_feats, train):
train = train[name_of_feats].copy()
for n in name_of_feats:
print(train[n].unique())
if len(name_of_feats) > 2:
for name in name_of_feats:
mask = train.isnull().any(axis = 1)
rows_w_nans_unique = train[mask].drop_duplicates()
display('unique combination of column values for columns with nans')
display(rows_w_nans_unique)
elif len(name_of_feats) == 2:
for n in name_of_feats:
feat_is_numeric = (train[n].dtype == np.float64) or (train[n].dtype == np.int64)
if feat_is_numeric:
is_0 = train[n] == 0
is__null = train[n].isnull() == False
is_more_than_0 = train[n] > 0
train[n] = train[n].astype('object')
train[n] = train[n].fillna('nan')
train[n][is_0] = 'zero'
train[n][is_more_than_0] = 'not_0'
else:
train[n] = train[n].astype('object')
train[n] = train[n].fillna('nan')
display(pd.crosstab(index = train[name_of_feats[0]],
columns = train[name_of_feats[1]]))
display(pd.crosstab(index = train[name_of_feats[0]],
columns = train[name_of_feats[1]], normalize = 'index'))
masonry_veneer = ['MasVnrType', 'MasVnrArea']
check_nans(masonry_veneer, train)
pd.crosstab(index = train['MasVnrType'], columns = train['MasVnrArea'])
['BrkFace' 'None' 'Stone' 'BrkCmn' nan]
[1.960e+02 0.000e+00 1.620e+02 3.500e+02 1.860e+02 2.400e+02 2.860e+02
3.060e+02 2.120e+02 1.800e+02 3.800e+02 2.810e+02 6.400e+02 2.000e+02
2.460e+02 1.320e+02 6.500e+02 1.010e+02 4.120e+02 2.720e+02 4.560e+02
1.031e+03 1.780e+02 5.730e+02 3.440e+02 2.870e+02 1.670e+02 1.115e+03
4.000e+01 1.040e+02 5.760e+02 4.430e+02 4.680e+02 6.600e+01 2.200e+01
2.840e+02 7.600e+01 2.030e+02 6.800e+01 1.830e+02 4.800e+01 2.800e+01
3.360e+02 6.000e+02 7.680e+02 4.800e+02 2.200e+02 1.840e+02 1.129e+03
1.160e+02 1.350e+02 2.660e+02 8.500e+01 3.090e+02 1.360e+02 2.880e+02
7.000e+01 3.200e+02 5.000e+01 1.200e+02 4.360e+02 2.520e+02 8.400e+01
6.640e+02 2.260e+02 3.000e+02 6.530e+02 1.120e+02 4.910e+02 2.680e+02
7.480e+02 9.800e+01 2.750e+02 1.380e+02 2.050e+02 2.620e+02 1.280e+02
2.600e+02 1.530e+02 6.400e+01 3.120e+02 1.600e+01 9.220e+02 1.420e+02
2.900e+02 1.270e+02 5.060e+02 2.970e+02 nan 6.040e+02 2.540e+02
3.600e+01 1.020e+02 4.720e+02 4.810e+02 1.080e+02 3.020e+02 1.720e+02
3.990e+02 2.700e+02 4.600e+01 2.100e+02 1.740e+02 3.480e+02 3.150e+02
2.990e+02 3.400e+02 1.660e+02 7.200e+01 3.100e+01 3.400e+01 2.380e+02
1.600e+03 3.650e+02 5.600e+01 1.500e+02 2.780e+02 2.560e+02 2.250e+02
3.700e+02 3.880e+02 1.750e+02 1.460e+02 1.130e+02 1.760e+02 6.160e+02
3.000e+01 1.060e+02 8.700e+02 3.620e+02 5.300e+02 5.000e+02 5.100e+02
2.470e+02 3.050e+02 2.550e+02 1.250e+02 1.000e+02 4.320e+02 1.260e+02
4.730e+02 7.400e+01 1.450e+02 2.320e+02 3.760e+02 4.200e+01 1.610e+02
1.100e+02 1.800e+01 2.240e+02 2.480e+02 8.000e+01 3.040e+02 2.150e+02
7.720e+02 4.350e+02 3.780e+02 5.620e+02 1.680e+02 8.900e+01 2.850e+02
3.600e+02 9.400e+01 3.330e+02 9.210e+02 5.940e+02 2.190e+02 1.880e+02
4.790e+02 5.840e+02 1.820e+02 2.500e+02 2.920e+02 2.450e+02 2.070e+02
8.200e+01 9.700e+01 3.350e+02 2.080e+02 4.200e+02 1.700e+02 4.590e+02
2.800e+02 9.900e+01 1.920e+02 2.040e+02 2.330e+02 1.560e+02 4.520e+02
5.130e+02 2.610e+02 1.640e+02 2.590e+02 2.090e+02 2.630e+02 2.160e+02
3.510e+02 6.600e+02 3.810e+02 5.400e+01 5.280e+02 2.580e+02 4.640e+02
5.700e+01 1.470e+02 1.170e+03 2.930e+02 6.300e+02 4.660e+02 1.090e+02
4.100e+01 1.600e+02 2.890e+02 6.510e+02 1.690e+02 9.500e+01 4.420e+02
2.020e+02 3.380e+02 8.940e+02 3.280e+02 6.730e+02 6.030e+02 1.000e+00
3.750e+02 9.000e+01 3.800e+01 1.570e+02 1.100e+01 1.400e+02 1.300e+02
1.480e+02 8.600e+02 4.240e+02 1.047e+03 2.430e+02 8.160e+02 3.870e+02
2.230e+02 1.580e+02 1.370e+02 1.150e+02 1.890e+02 2.740e+02 1.170e+02
6.000e+01 1.220e+02 9.200e+01 4.150e+02 7.600e+02 2.700e+01 7.500e+01
3.610e+02 1.050e+02 3.420e+02 2.980e+02 5.410e+02 2.360e+02 4.230e+02
4.400e+01 1.510e+02 9.750e+02 4.500e+02 2.300e+02 5.710e+02 2.400e+01
5.300e+01 2.060e+02 1.400e+01 3.240e+02 2.950e+02 3.960e+02 6.700e+01
1.540e+02 1.440e+02 4.250e+02 4.500e+01 1.378e+03 3.370e+02 1.490e+02
1.430e+02 5.100e+01 1.710e+02 2.340e+02 6.300e+01 7.660e+02 3.200e+01
8.100e+01 1.630e+02 5.540e+02 2.180e+02 6.320e+02 1.140e+02 5.670e+02
3.590e+02 4.510e+02 6.210e+02 7.880e+02 8.600e+01 3.910e+02 2.280e+02
8.800e+01 1.650e+02 4.280e+02 4.100e+02 5.640e+02 3.680e+02 3.180e+02
5.790e+02 6.500e+01 7.050e+02 4.080e+02 2.440e+02 1.230e+02 3.660e+02
7.310e+02 4.480e+02 2.940e+02 3.100e+02 2.370e+02 4.260e+02 9.600e+01
4.380e+02 1.940e+02 1.190e+02]
| MasVnrArea | nan | not_0 | zero |
|---|---|---|---|
| MasVnrType | |||
| BrkCmn | 0 | 15 | 0 |
| BrkFace | 0 | 442 | 1 |
| None | 0 | 5 | 858 |
| Stone | 0 | 125 | 1 |
| nan | 8 | 0 | 0 |
| MasVnrArea | nan | not_0 | zero |
|---|---|---|---|
| MasVnrType | |||
| BrkCmn | 0.0 | 1.000000 | 0.000000 |
| BrkFace | 0.0 | 0.997743 | 0.002257 |
| None | 0.0 | 0.005794 | 0.994206 |
| Stone | 0.0 | 0.992063 | 0.007937 |
| nan | 1.0 | 0.000000 | 0.000000 |
| MasVnrArea | 0.0 | 1.0 | 11.0 | 14.0 | 16.0 | 18.0 | 22.0 | 24.0 | 27.0 | 28.0 | ... | 921.0 | 922.0 | 975.0 | 1031.0 | 1047.0 | 1115.0 | 1129.0 | 1170.0 | 1378.0 | 1600.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MasVnrType | |||||||||||||||||||||
| BrkCmn | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BrkFace | 1 | 0 | 1 | 1 | 6 | 2 | 1 | 0 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| None | 858 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Stone | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
4 rows × 324 columns
area_0_to_drop = train[train.MasVnrArea == 0]
stone_to_drop = area_0_to_drop[train.MasVnrType == 'Stone'].index.values
brickface_to_drop = area_0_to_drop[train.MasVnrType == 'BrkFace'].index.values
train = train.drop(stone_to_drop)
train = train.drop(brickface_to_drop)
no_mv = train[train.MasVnrType == 'None']
area_not_zero_to_drop = no_mv[no_mv.MasVnrArea > 0].index.values
train = train.drop(area_not_zero_to_drop)
Replacing Nans in Masonry Veneer Columns
For MasVnrArea, I will replace nans with mean. For MasVnrType, I will replace nans with the mode because it is a categorical feature so it does not have a mean.
hist_before_nan_to_mean(train.MasVnrArea)
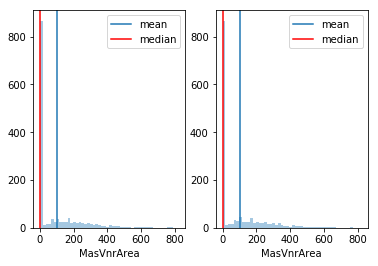
train.MasVnrArea = train.MasVnrArea.fillna(train.MasVnrArea.mean())
train.MasVnrType = train.MasVnrType.fillna(train.MasVnrType.mode()[0])
Pickling
Why not store dataframe and functions to pass to other notebooks?
We can store dataframes by running %store train_df and grab it in another notebook by running %store -r train_df. However, you need to always run this notebook first, where we store train_df. When we pickle, we do not need to rerun the notebook where we store train_df.
Also, we cannot store functions.
Pickling makes more sense.
train.to_pickle('../data/train.p')