
Predicting Housing Prices 04 Benchmarking With Linear Regression
import numpy as np
import pandas as pd
import pickle
import warnings; warnings.filterwarnings('ignore')
import sklearn.preprocessing as preprocessing
import matplotlib.pyplot as plt
from sklearn import linear_model
Benchmarking
We need to get a basis for comparison to get a sense of what a “good” model is for this task. We’ll use a basic linear regression.
Unpickling
test = pd.read_pickle('../data/test.p')
train = pd.read_pickle('../data/train.p')
target = ['SalePrice']
X = train.drop(columns=target)
y = train.SalePrice
One-Hot Encoding Necessary for Linear Regression
sklearn.linear is aware of the dummy variable trap and will drop the collinear columns for you. You don’t need to drop them, but it’s good practice to drop them yourself.
Why Scale Dummy Variables
There is a lot of disagreement at least on StackOverflow. We will take the recommendation of the man who literally wrote the book on LASSO and regularization, Tibshirani THE LASSO METHOD FOR VARIABLE SELECTION IN THE COX MODEL, Statistics in Medicine, VOL. 16, 385-395 (1997)
The lasso method requires initial standardization of the regressors, so that the penalization scheme is fair to all regressors. For categorical regressors, one codes the regressor with dummy variables and then standardizes the dummy variables. As pointed out by a referee, however, the relative scaling between continuous and categorical variables in this scheme can be somewhat arbitrary.
Scaling does make interpreting the coefficients of dummied predictors harder.
X_dummies = pd.get_dummies(X, drop_first = True)
Split Train Set Into Train and Validation Set
from sklearn.model_selection import train_test_split
X_train, X_vdn, y_train, y_vdn = train_test_split(X_dummies,y)
Scaling
Why Scale Dummy Variables
There is a lot of disagreement at least on StackOverflow. We will take the recommendation of the man who literally wrote the book on LASSO and regularization, Tibshirani THE LASSO METHOD FOR VARIABLE SELECTION IN THE COX MODEL, Statistics in Medicine, VOL. 16, 385-395 (1997)
The lasso method requires initial standardization of the regressors, so that the penalization scheme is fair to all regressors. For categorical regressors, one codes the regressor with dummy variables and then standardizes the dummy variables. As pointed out by a referee, however, the relative scaling between continuous and categorical variables in this scheme can be somewhat arbitrary.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_vdn_scaled = scaler.transform(X_vdn)
Modeling With Linear Regression
from sklearn.metrics import mean_squared_log_error
def rmsle(y_true, y_pred):
return np.sqrt(mean_squared_log_error(y_true, y_pred))
lr = linear_model.LinearRegression()
un-scaled data
lr_raw = lr.fit(X_train, y_train)
lr_raw.score(X_train, y_train)
0.9632651513224931
lr_raw.score(X_vdn, y_vdn)
0.8152054960736487
scaled data
lr_scaled = lr.fit(X_train_scaled, y_train)
lr_scaled.score(X_train_scaled, y_train)
0.9632631931581587
lr_scaled.score(X_vdn_scaled, y_vdn)
-4.0461978857851775e+20
Why Scaled Data Leads To A Better Model
Our features in the raw data are on different scales so some will stand out as more informative when they really aren’t.
Why This Linear Regression Performs Poor
There is a lot of multicollinearity in the data and linear regression performs poorly on data with multicollinearity (unlike decision trees for example).
How to Make Linear Regression More Robust to Multicollinearity
We can remove multicollinearity by removing collinear features. That actually is the ideal solution. We do not want redundant features even on a model that is robust to multicollinearity such as decision trees. However, that is a lot of work.
An easier approach is to add a penalty. LASSO introduces the L1 penalty. Ridge introduces the L2 penalty. For more about LASSO and the L1 penalty, read my write-up on LASSO.
Now Testing Linear Regression with Test Set
Have to append test to X because in case there are values in test and not in X and vice versa.
rows_test = set(test.index)
rows_train = set(X.index)
rows_test & rows_train
set()
dummies = pd.get_dummies(X.append(test), drop_first= True)
X_dummies = dummies.loc[list(rows_train)]
test_dummies = dummies.loc[list(rows_test)]
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_dummies)
test_scaled = scaler.transform(test_dummies)
lr = linear_model.LinearRegression()
lr.fit(X_scaled, y)
print('lr.score(X_scaled, y) = ', lr.score(X_scaled, y))
print('rmsle = ', rmsle(lr.predict(X_scaled), y))
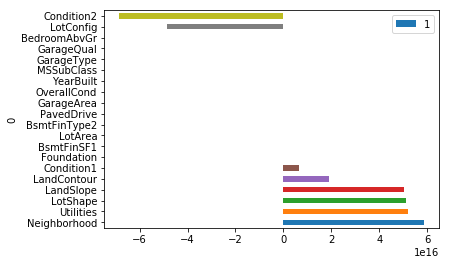
def plot_coef(model, top_n = 10):
'''
Plots the magnitude of coefficients
'''
cols = X.columns
coef = model.coef_
zipped = list(zip(cols, coef))
zipped.sort(key=lambda x: x[1], reverse = True)
top_10 = pd.DataFrame(zipped).head(top_n)
bottom_10 = pd.DataFrame(zipped).tail(top_n)
return pd.concat([top_10, bottom_10], axis=0).plot.barh(x = 0, y = 1)
plot_coef(lr)
lr.score(X_scaled, y) = 0.9525399113076025
rmsle = 0.0978013389202143
<matplotlib.axes._subplots.AxesSubplot at 0x21f6ab08550>
submission = pd.DataFrame({'SalePrice': lr.predict(test_scaled)},
index = test.index)
submission.to_csv('ames-submission.csv')
Kaggle
For this competition, Kaggle uses the root mean square log error.

